We've discussed the fundamental motivation behind the decoupling of data from containers in Docker Bind Mounts: A quick summary: Containers are not able to permanently modify the filesystem of their underlying image, thus all modifications to the filesystem will be removed along with the container. If you want to persist data generated by a container, you have to outsource that data to the host system. The preferred way of doing this are Docker Volumes.
Differences and Advantages Over Bind Mounts
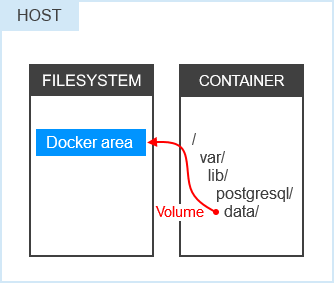
Unlike with bind mounts, the user doesn't specify a host directory that they want to mount into the container. Instead, the user specifies a directory in the container that should be integrated as a volume. The volume and its data is then stored in a Docker-managed area on the host system.
This concept brings some advantages compared to the more traditional bind mounts.
- Volumes can be named, making them easy to handle.
- Users don't have to manage the storage location themselves.
- Volumes are first-class citizens in Docker and thereby manageable via the CLI.
- For an arbitrary scenario, volumes can use a volume driver that fits best.
- Docker completely manages volumes itself while considering custom settings.
Let me give an example: The official PostgreSQL image stores its data in /var/lib/postgres/data, which is mounted as a
volume here. Syntactically, the corresponding command only differs from a bind mount in that the host directory is
missing.
$ docker container run -d \ --name database \ -v /var/lib/postgres/data \ postgres
Creating Named Volumes
In the example above, I've completely outsourced the PostgreSQL data into an own volume. This volume has been created as an anonymous volume because there was no volume name specified. Running the following command indicates that the volume got a random digest as name instead:
$ docker volume ls
DRIVER VOLUME NAME
local 21aef22affde3ed4ede8c0d66092f73240147099856688389256c05ddd311da8
To simplify the management and maintenance, an explicit name can be assigned to a volume. When using the -v option,
this can be accomplished by putting a name like pg-data in front of the filepath.
$ docker container run -d \ --name database \ -v pg-data:/var/lib/postgres/data \ postgres
A named volume can also be created independently of a container:
$ docker volume create pg-data
docker volume create allows the user to specify arbitrary options, such as the use of a different volume driver. Once
a volume is created, it is manageable via the Docker CLI as a first-class citizen. You can remove the created volume and
its data using docker volume rm pg-data.
Why --mount Is Preferable
If the -v pg-data:/var/lib/postgres/data seems familiar to you, you have probably come into contact with bind mounts
already. Unfortunately, the only syntactical difference between a named volume and a bind mount is that the syntax for
a bind mount expects an absolute path. An option like -v $(pwd)/pg-data:/var/lib/postgres/data would have created a
bind mount instead of a volume. This slight difference is confusing even for more experienced users.
To avoid unnecessary confusion at this point, it is very advisable to rely on the more readable --mount option
with its self-explanatory syntax instead. Paying attention whether the first argument is a volume name or an absolute
path isn't necessary here, because the mount type is specified explicitly.
$ docker container run -d \ --name database \ --mount type=volume,source=pg-data,destination=/var/lib/postgres/data \ postgres
Create a Backup Using Temporary Containers
The fact that all volume data is exclusively managed by Docker doesn't mean that we cannot work with the data anymore. A volume's name provides a valid reference for working with that data.
Given the scenario that the PostgreSQL container database stores its data in a volume named pg-data and we want to
create a backup in the local directory db-backup, there are a number of well-understood patterns for doing this. One
of them is to create a temporary container which mounts the volume and copies data into a target directory.
$ docker container run -d \ --rm \ --mount type=volume,source=pg-data,destination=/from \ --mount type=bind,source=$(pwd)/db-backup,destination=/to \ ubuntu \ tar cvf /to/backup.tar /from
After mounting the data volume into the /from directory and bind mounting db-backup into the /to directory, all
that has to be done is copying the contents of /from into /to. This example command even goes a bit further as it
packs the volume data in a TAR. We've obtained the volume data as an archive stored on the host system as a result.
Thus, volumes are a perfect fit for making data independent of the container working with it. Since they are highly flexible and even provide the possibility to store data on a different host or in a cloud storage like AWS S3, you will come into contact with them sooner or later for sure.